


 2026西湖龙井茶官网DTC发售:茶农直供,政府溯源防伪到农户家
2026西湖龙井茶官网DTC发售:茶农直供,政府溯源防伪到农户家
最便宜的大语言模型调用是你根本不去调用的那一次。
每个使用大语言模型进行开发的团队最终都会遇到同样的瓶颈。原型
运行良好,用户量攀升,突然之间应用程序接口账单开始出现无人预料的状况。
问题通常不在于人工智能昂贵,而在于团队将本不该由模型处理的工作交给了模型。
在你争论选择 GPT、Claude 还是 Gemini 之前,先问一个更基本的问题:
你真的需要大语言模型吗?
原则:仅在任务需要处理歧义、判断、综合、灵活的自然语言生成、复杂推理或工具使用时才使用大语言模型。不要仅仅因为“人工智能”这个词在架构图中看起来好看就使用它。
无模型审计
令人震惊的是,生产环境中大量大语言模型的支出实际上是昂贵的粘合剂,用于连接那些确定性代码、专用应用程序接口或更便宜的机器学习服务已经能很好处理的工作。
| 任务 | 在使用大语言模型之前先尝试此处 | 何时使用大语言模型 |
|---|---|---|
| 会议转录 | 专用语音转文本服务 | 你需要内容综合、后续事项提取或对行动项进行判断。 |
| 翻译 | 翻译应用程序接口或更便宜的模型 | 任务需要语气适配、上下文感知的重写或多语言推理。 |
| 结构化文档提取 | 光学字符识别、文档解析器、类似亚马逊网络服务 Textract 的流水线 | 文档布局混乱、字段含义模糊或需要类人解读。 |
| 小型分类法分类 | 关键词规则、正则表达式、小型分类器 | 类别重叠、标签主观或置信度低。 |
| 格式化和验证 | 模式验证、确定性代码 | 输出需要自然语言修复或解释。 |
表 1. 无模型审计:在使用大语言模型之前的更廉价初步替代方案。
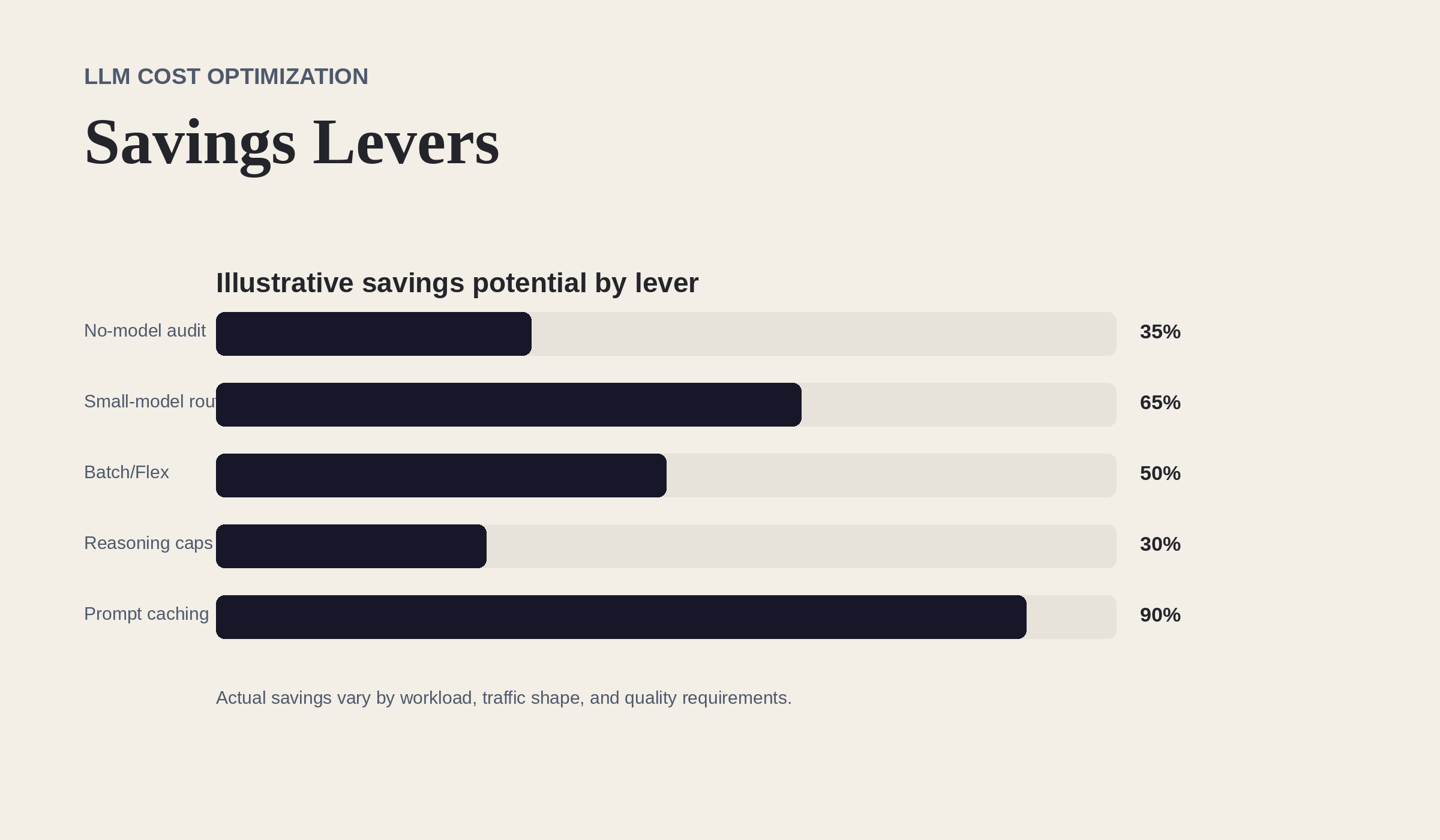
团队浪费金钱的地方

图 1. 无模型优先审计防止团队为确定性工作支付前沿模型的价格。
常见的模式很简单。团队构建一个通用提示词,将所有请求指向一个强大的模型,然后发布。它奏效了,所以在账单到来之前没人质疑架构。到那时,模型已成为分类、提取、路由、格式化、翻译、重写和异常处理的默认路径。
这是本末倒置。模型不应是默认路径。模型应是判断路径。
















{kind=link}