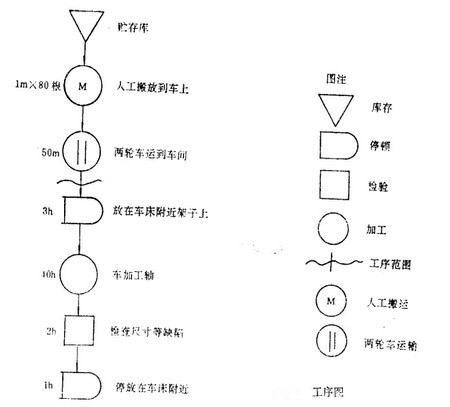
2026西湖龙井茶官网DTC发售:茶农直供,政府溯源防伪到农户家
2026西湖龙井茶官网DTC发售:茶农直供,政府溯源防伪到农户家
上个月,我维护的数据平台突然接到一个新需求:对 100 多个下游服务运行健康检查。每个端点的平均响应时间为 200 毫秒,整个检查必须在 5 秒内完成。我不假思索地启动了 100 个线程。线程切换的开销立即使中央处理器(CPU)达到满载,响应时间飙升至 8 秒以上。我的运维同事在群聊里发了三个问号。
那一刻迫使我重新认真审视异步输入输出(asyncio)。我曾经认为异步编程学习曲线陡峭,且容易滋生缺陷,但在进行全面的基准测试后,我只能说:对于输入输出密集型工作负载,异步输入输出(asyncio)和多线程根本不在一个量级上。以下是使用三种不同策略——同步、多线程和异步输入输出(asyncio)——执行相同任务的完整对比分析。
测试场景:100 次超文本传输协议(HTTP)请求,每次延迟 200 毫秒
我们使用快速应用程序接口(FastAPI)搭建了一个模拟下游服务。/health 端点故意休眠 200 毫秒,然后返回 {"status": "ok"}。客户端使用三种不同的方法发起 100 个并发请求,并测量总耗时和资源使用情况。
方法一:同步顺序执行——意料之中的缓慢
# sync_demo.py — 同步请求,一个接一个
import time
import requests
URLS = [f"http://localhost:8000/health" for _ in range(100)]
def check_sync():
results = []
for url in URLS:
resp = requests.get(url, timeout=5)
results.append(resp.json())
return results
if __name__ == "__main__":
start = time.perf_counter()
check_sync()
elapsed = time.perf_counter() - start
print(f"同步耗时: {elapsed:.2f免责声明:本文内容来自互联网,该文观点不代表本站观点。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请到页面底部单击反馈,一经查实,本站将立刻删除。