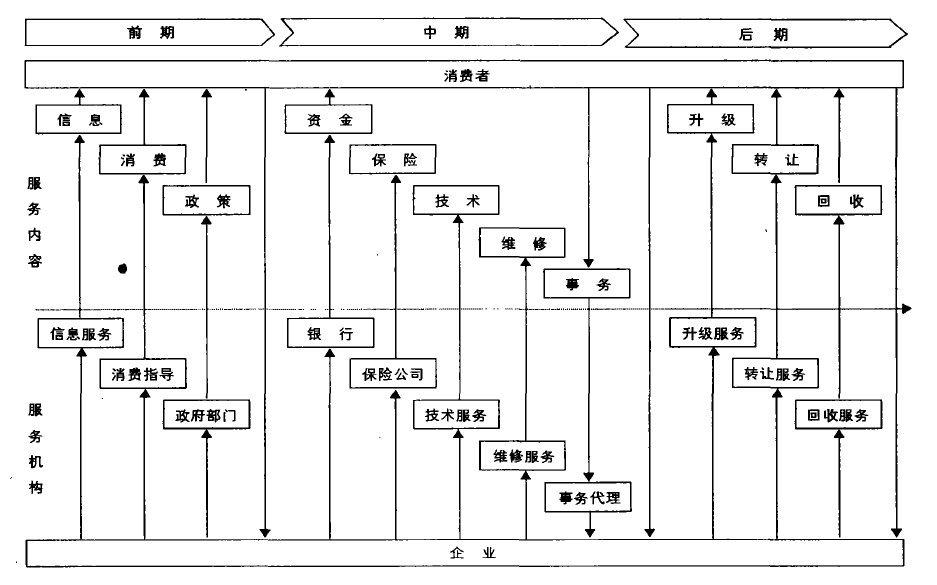
库伯内特斯和人工智能已成为不太可能的合作伙伴——数据证明了这一点。来自云原生计算基金会和 SlashData 的新数据显示,三分之二运行生成式人工智能模型的组织已选择库伯内特斯作为编排标准。但关键在于:这并不是因为库伯内特斯能神奇地解决人工智能问题。而是因为使库伯内特斯具有价值的工程基础——标准化、可重复性、资源隔离——正是人工智能工作负载在从笔记本电脑环境走向生产环境时所必需的。
如果您正在构建或扩展人工智能系统,这不仅仅是趣闻轶事。这是一个表明行业融合方向的信号,而库伯内特斯是否适合您,较少取决于炒作,更多取决于您实际试图实现的目标。
数据背后的真实故事
让我们明确一点:库伯内特斯成为人工智能的首选平台,并不是因为它是为大型语言模型或模型推理专门构建的。它成为默认选择是因为:
- 跨团队标准化:当您的数据科学家、机器学习工程师和基础设施团队都在交付模型时,库伯内特斯提供了统一的部署目标。不再出现“在我的机器上可以运行”这种碎片化问题。
- 资源编排:人工智能工作负载资源需求巨大。图形处理器、加速器、内存——库伯内特斯将这些抽象化,让您能够定义每个模型的需求,而无需手动配置。
- 大规模多租户支持:如果您为不同的团队或产品运行多个模型,隔离性和公平的资源分配变得不可或缺。
但数据真正强调的是:人工智能的成功仍然归结于枯燥的基础性工作。获胜的团队并不是那些找到了完美库伯内特斯 YAML 模板的团队。而是那些拥有稳固的内部开发者平台、清晰的可观测性,并 relentlessly 专注于开发者体验的团队。
每个人工智能团队都需要回答的内部开发者平台问题
这项研究最重要的启示是对内部开发者平台的强调。原因如下:
人工智能团队行动迅速,但往往缺乏传统后端团队的运营成熟度。他们希望快速实验、迭代和交付。但如果没有抽象层,您无法实现规模化。
一个有效的人工智能内部开发者平台位于您的数据科学家(希望交付模型)和库伯内特斯(处理编排)之间。它提供:
- 自助式模型部署:数据科学家提交模型;平台处理图形处理器分配、版本控制和回滚。
- 标准化可观测性:针对推理端点的指标、日志和追踪——不仅供运维团队使用,也供机器学习团队早期发现漂移和性能下降。
- 成本可见性:人工智能成本高昂。您的内部开发者平台应向团队准确显示其模型的运行成本。
# 示例:简化的模型部署抽象
apiVersion: ml.company.io/v1
kind: ModelEndpoint
metadata:
name: gpt-classifier-prod
spec:
model: gcr.io/company/gpt-classifier:v2.1.3
resources:
accelerators: "免责声明:本文内容来自互联网,该文观点不代表本站观点。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请到页面底部单击反馈,一经查实,本站将立刻删除。