




智猩猩GenAI整理
编辑:六一
测试时扩展推动了复杂推理领域的重大进展,DeepSeek-R1、Gemini-2.5等领先模型表明,扩展思维链,本质上"更长时间地思考"能显著提升性能,尤其当通过RLVR优化时。然而,对于容易产生微妙中间错误或需要创造性思维转变的难题,长思维链仍存在根本性局限,模型依赖内部自我反思往往无法检测错误,或在初始方法存在缺陷时无法自我修正。
为此,微软提出rStar2-Agent,一个14B数学推理AI Agent模型,通过开发更高级的认知能力使其"更聪明地思考",这些能力可以自主地利用正确的工具进行推理、验证并从工具环境提供的反馈信号中学习。具体实现依赖于三大关键创新:(i)配备可靠Python代码环境的高效强化学习基础设施,支持高吞吐量执行并降低rollout成本,仅用有限GPU资源即可完成训练;(ii)GRPO-RoC算法,采用正确重采样rollout策略的智能体强化学习方法,有效应对编程工具固有的环境噪声,使模型在代码环境中能更高效推理;(iii)分阶段的高效智能体训练方案:从非推理监督微调(SFT)起步,逐步过渡到多阶段强化学习,以最小计算成本获得高级认知能力。
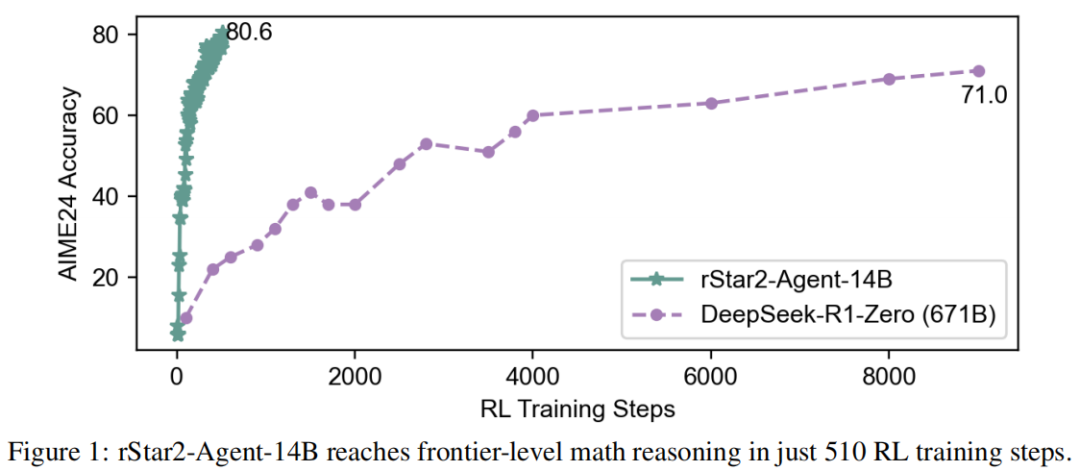
基于此,论文仅用510步强化学习训练(一周内)就使14B参数预训练模型达顶尖水平,以更简短的响应超越DeepSeek-R1(671B)。除数学领域外,rStar2-Agent-14B还在对齐任务、科学推理和智能体工具使用等场景展现出卓越的泛化能力。

论文标题:rStar2-Agent: Agentic Reasoning Technical Report
论文链接:https://arxiv.org/abs/2508.20722v1
项目地址:https://github.com/microsoft/rStar
01
GRPO-RoC算法
为实现代码环境中有效的智能体强化学习,论文提出基于正确重采样的群组相对策略优化方法(GRPO-RoC)。该方法将GRPO与正确重采样(RoC)的rollout策略相结合,以解决稀疏结果性奖励下环境引发的噪声问题。
具体而言,RoC首先生成超量的rollout样本组,随后向下采样至标准批次规模:通过筛选保留工具使用错误最少、格式问题最小的高质量正轨迹,同时对负轨迹进行均匀下采样。
这种简单有效的不对称采样策略,既保留了多样化的失败模式作为信息丰富的负向信号,又强化了高质量成功案例的正向监督。相较于在奖励函数中显式惩罚工具使用错误的方法,GRPO-RoC提升了训练稳定性并规避了奖励黑客(reward-hacking)风险。
02
基础设施
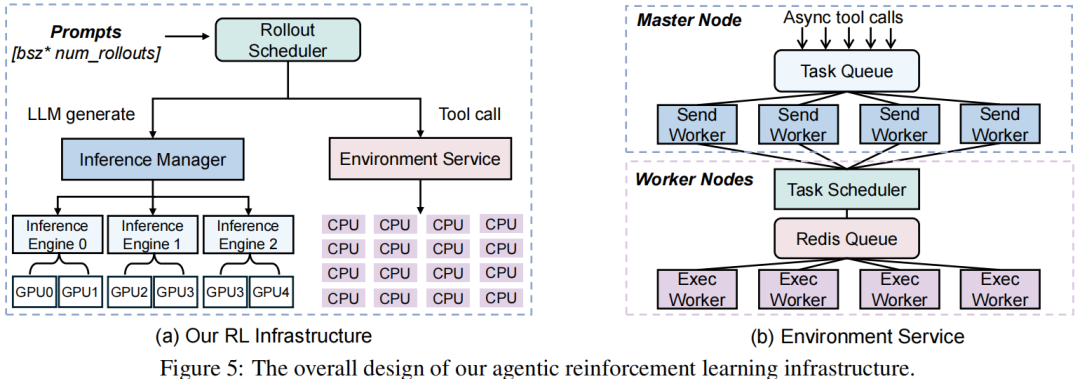
论文在VERL v0.2和SGLang基础上构建了用于大规模智能体强化学习基础设施。
1.可靠的高吞吐量代码环境
如图5(b)所示,论文的环境服务设计主要围绕两个核心目标:一是将服务与主训练过程隔离的同时最大化资源利用率;二是支持海量并发工具调用并快速返回执行结果。
该服务部署在训练集群的CPU核心上。主节点的中央任务队列接收请求,多个发送worker持续轮询该队列,将工具调用打包成批次分发至工作节点,工作节点的任务调度器将传入批次的工具调用动态分配给空闲执行worker,确保负载均衡。执行完成后结果返回至发送worker,最终传回RL rollout进程。
经测量,每个训练步骤可生成高达4.5万次工具调用,该服务仍同时实现高吞吐量(每步45次调用)和低延迟(单次调用0.3秒,含调度与执行时间),证明其能支撑大规模训练。
2.负载均衡的Rollout调度器
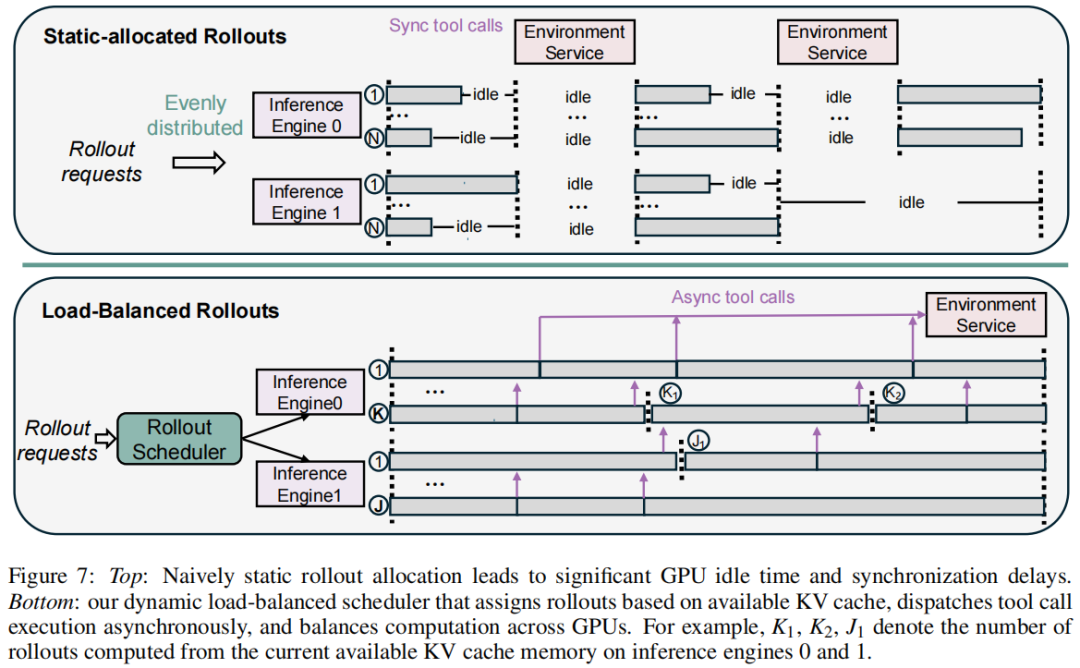
静态Rollout分配存在负载不均、同步延迟与KV缓存溢出等问题,为此,论文引入了动态负载均衡rollout调度方法(图7下)。
动态rollout调度器根据各GPU当前可用KV缓存容量来分配请求。具体而言:给定最大rollout长度L,估算每个GPU在不超过KV缓存限制的前提下可安全处理的最大rollout数量K(K < N)。每个GPU随后独立执行分配的rollout。在多轮rollout过程中,工具调用在生成后立即异步分发至环境服务,消除了等待其他rollout造成的空闲时间。当GPU完成指定请求并释放KV缓存空间后,调度器实时分配新请求,确保跨GPU的工作负载均衡。该方法显著提升了GPU利用率和整体rollout效率。
03
训练方法
1.非推理冷启动
与先前研究在监督微调(SFT)阶段引入大量推理数据不同,论文方法在此阶段仅专注于通用指令遵循、JSON格式化和基础编码工具使用,这些对智能体强化学习至关重要。
采用Qwen3-14B-base作为基座模型,收集相关数据,经过非推理式监督微调后,模型在工具使用、指令遵循和对话能力方面有所提升,同时保持与基础模型相当的数学推理能力。
2.多阶段强化学习训练
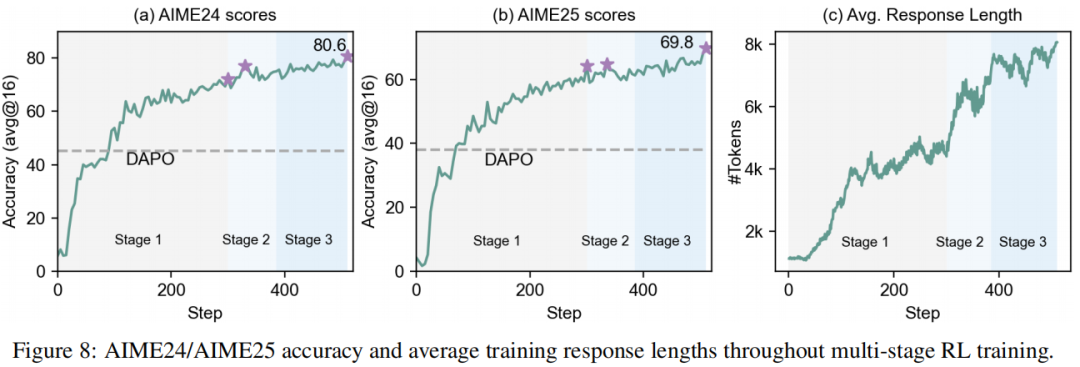
采用GRPO-RoC算法进行大规模智能体强化学习,各阶段详细说明如下:
强化学习第一阶段:8K响应长度的简洁训练
第一阶段使用最大响应长度8K token在全部4.2万条精选数学问题上进行训练,平均响应长度从约1K个token开始,逐渐增加并稳定在约4K个token。评估分数持续提升,响应变得更为简洁,表明较短长度预算下的简洁训练不仅能提升训练效率,还能在早期促进更强推理能力,为后续阶段奠定坚实基础。
强化学习第二阶段:扩展至12K响应长度
8K最大响应长度成为进一步学习的限制因素。因此第二阶段将最大响应长度增加至12K token。如图8所示,此扩展使平均响应长度从4K增至6K,并在AIME24和AIME25评估中持续提升性能。
强化学习第三阶段:难题聚焦训练
到第二阶段末期,批次中超过70%的问题因达到完美通过率1而被剔除,说明许多问题对模型已过于简单。为保持训练有效性,在第三阶段转向难题训练,采用离线过滤策略:使用最新策略在原始4.2万条问题上为每个问题生成8个rollout,剔除全部8次回答正确的问题,得到1.73万个难题。在此数据集训练时,重置优化器状态并将参考模型更新为最新策略。
如图8所示,聚焦难题训练进一步提升了性能,平均响应长度从6K增至8K。经过额外125步训练,该阶段将14B参数模型逐步推至数学推理前沿水平。
04
实验
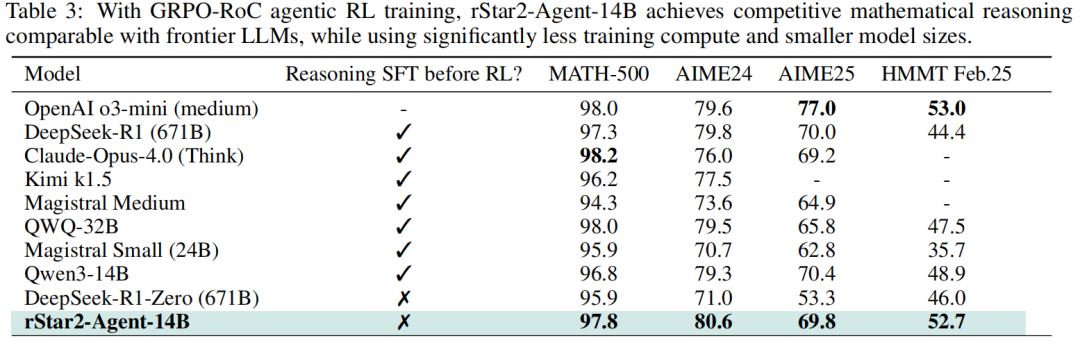
实验结果显示,14B的rStar2-Agent靠高效智能体强化学习便展现出了强大的数学推理能力,持平甚至超越训练成本更高、参数量更大的前沿大语言模型。这些成果在14B小规模参数和高性价比训练计算(64张MI300X GPU上510个RL步骤)的背景下尤为瞩目。
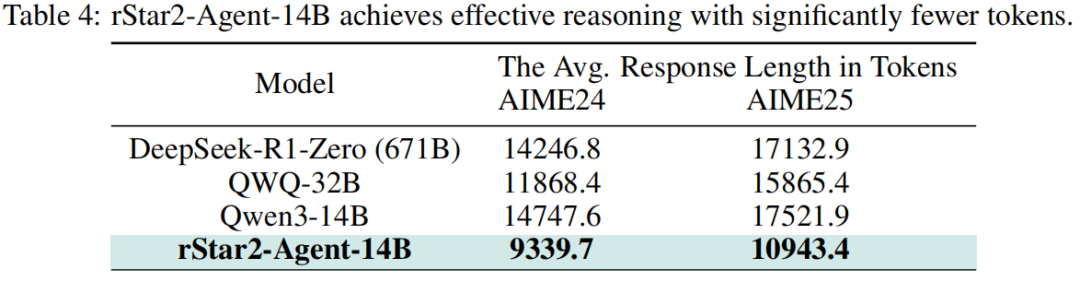
rStar2-Agent不仅实现了强大的推理能力,更以更少token达成更高效推理。表4显示rStar2-Agent-14B生成更短响应,却在挑战性问题上获得更高推理准确率。表明通过强化更高质量的正向轨迹,模型已学会更智能地使用编码工具进行高效推理。
END
✦
✦
报告推荐
✦
✦
✦
推荐阅读
✦
突破任意比特通信瓶颈!美团英伟达提出FlashCommunication V2,加速LLM分布式训练与部署
LLM后训练新范式!字节提出后完成学习PCL:在后完成空间进行SFT与RL混合训练
图灵奖得主Sutton最新成果!拓展强化学习到控制领域,有望媲美深度强化学习
Hugging Face周榜第一!人大高瓴与快手联合提出ARPO强化学习算法,专为Agent而生
华人团队开源世界首个多智能体记忆系统MIRIX:准确率较Gemini提高410%,存储需求降了9成
点击下方名片 即刻关注我们
















